讓問答更自然 - 基于拷貝和檢索機制的自然答案生成系統(tǒng)研究
- 2017-05-15 15:43:39
摘要:讓機器像人類一樣擁有智能是研究人員一直以來的奮斗目標。由于智能的概念難以確切定義,圖靈提出了著名的圖靈測試(Turning Test):如果一臺機器能夠與人類展開對話而不能被辨別出其機器身份,那么稱這臺機器具有智能。圖靈測試一直以來都被作為檢驗人工智能的象征。問答系統(tǒng)本身就是圖靈測試的場景,如果我們有了和人一樣的智能問答系統(tǒng),那么就相當于通過了圖靈測試,因此問答系統(tǒng)的研究始終受到很大的關注。
讓機器像人類一樣擁有智能是研究人員一直以來的奮斗目標。由于智能的概念難以確切定義,圖靈提出了著名的圖靈測試(Turning Test):如果一臺機器能夠與人類展開對話而不能被辨別出其機器身份,那么稱這臺機器具有智能。圖靈測試一直以來都被作為檢驗人工智能的象征。問答系統(tǒng)本身就是圖靈測試的場景,如果我們有了和人一樣的智能問答系統(tǒng),那么就相當于通過了圖靈測試,因此問答系統(tǒng)的研究始終受到很大的關注。
傳統(tǒng)知識問答都是針對用戶(使用自然語言)提出的問句,提供精確的答案實體,例如:對于問句“泰戈爾的出生地在哪兒?”,返回“加爾各答”。但是,僅僅提供這種孤零零的答案實體并不是非常友好的交互方式,用戶更希望接受到以自然語言句子表示的完整答案,如“印度詩人泰戈爾出生于加爾各答市”。自然答案可以廣泛應用有社區(qū)問答、智能客服等知識服務領域。知識問答中自然答案的生成在具有非常明確的現(xiàn)實意義和強烈的應用背景。
 與返回答案實體相比,知識問答中返回自然答案有如下優(yōu)勢:
1. 普通用戶更樂于接受能夠自成一體的答案形式,而不是局部的信息片段。
2. 自然答案能夠?qū)卮饐柧涞倪^程提供某種形式的解釋,還可以無形中增加用戶對系統(tǒng)的接受程度。
3. 自然答案還能夠提供與答案相關聯(lián)的背景信息(如上述自然答案中的“印度詩人”)。
4. 完整的自然語言句子可以更好地支撐答案驗證、語音合成等后續(xù)任務。
但是讓知識問答系統(tǒng)生成自然語言形式的答案并不是一件容易的事情。目前,基于深度學習的語言生成模型大多基于原始數(shù)據(jù)學習數(shù)值計算的模型,如何在自然答案生成過程中融入符號表示的外部知識庫是一個大的挑戰(zhàn)。另外,很多問句的回答需要利用知識庫中的多個事實,并且一個自然答案的不同語義單元(詞語、實體)可能需要通過不同途徑獲得, 回答這種需要使用多種模式提取和預測語義單元的復雜問句,給自然答案的生成帶來了更大的挑戰(zhàn)。
為了解決這些問題,中科院自動化所的何世柱博士、劉操同學、劉康老師和趙軍老師在今年的 ACL2017 上發(fā)表了論文「Generating Natural Answers by Incorporating Copying and Retrieving Mechanisms in Sequence-to-Sequence Learning」,提出了端到端的問答系統(tǒng) COREQA,它基于編碼器-解碼器(Encoder-Decoder)的深度學習模型,針對需要多個事實才能回答的復雜問句,引入了拷貝和檢索機制,從不同來源,利用拷貝、檢索和預測等不同詞匯獲取模式,獲得不同類型的詞匯,對應復雜問句中答案詞匯的不同部分,從而生成復雜問句的自然答案。
與返回答案實體相比,知識問答中返回自然答案有如下優(yōu)勢:
1. 普通用戶更樂于接受能夠自成一體的答案形式,而不是局部的信息片段。
2. 自然答案能夠?qū)卮饐柧涞倪^程提供某種形式的解釋,還可以無形中增加用戶對系統(tǒng)的接受程度。
3. 自然答案還能夠提供與答案相關聯(lián)的背景信息(如上述自然答案中的“印度詩人”)。
4. 完整的自然語言句子可以更好地支撐答案驗證、語音合成等后續(xù)任務。
但是讓知識問答系統(tǒng)生成自然語言形式的答案并不是一件容易的事情。目前,基于深度學習的語言生成模型大多基于原始數(shù)據(jù)學習數(shù)值計算的模型,如何在自然答案生成過程中融入符號表示的外部知識庫是一個大的挑戰(zhàn)。另外,很多問句的回答需要利用知識庫中的多個事實,并且一個自然答案的不同語義單元(詞語、實體)可能需要通過不同途徑獲得, 回答這種需要使用多種模式提取和預測語義單元的復雜問句,給自然答案的生成帶來了更大的挑戰(zhàn)。
為了解決這些問題,中科院自動化所的何世柱博士、劉操同學、劉康老師和趙軍老師在今年的 ACL2017 上發(fā)表了論文「Generating Natural Answers by Incorporating Copying and Retrieving Mechanisms in Sequence-to-Sequence Learning」,提出了端到端的問答系統(tǒng) COREQA,它基于編碼器-解碼器(Encoder-Decoder)的深度學習模型,針對需要多個事實才能回答的復雜問句,引入了拷貝和檢索機制,從不同來源,利用拷貝、檢索和預測等不同詞匯獲取模式,獲得不同類型的詞匯,對應復雜問句中答案詞匯的不同部分,從而生成復雜問句的自然答案。
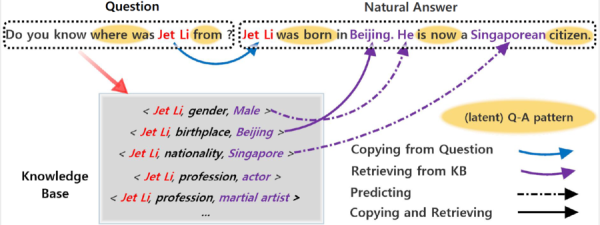 那么具體是怎么做的呢? 這里以“你知道李連杰來自哪里嗎?” 這個問題為例來說明:
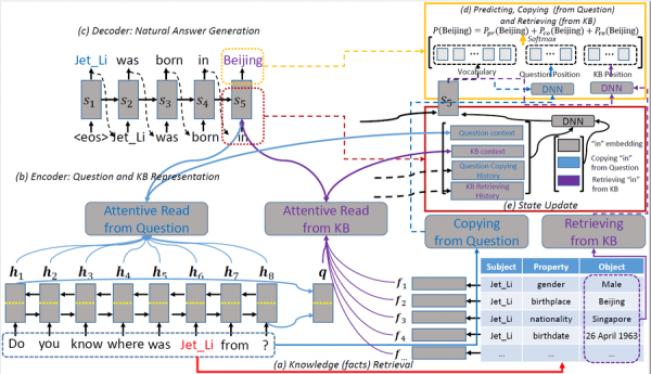
1. 知識檢索:首先要先識別問題中的包含的實體詞。這里我們識別出的實體詞是:李連杰。然后根據(jù)實體詞從知識庫(Knowledge Base,KB)中檢索出相關的三元組(主題,屬性,對象)。針對李連杰這個實體,我們可以檢索出(李連杰,性別,男),(李連杰,出生地,北京),(李連杰,國籍,新加坡)等三元組。
2. 編碼(Encoder):為了生成答案,我們需要將問題和檢索到的知識編碼成向量,以便后續(xù)深度生成模型利用。
問題編碼:使用了雙向 RNN(Bi-RNN),用兩種方式來表示問題:一種是將兩種方向 RNN 狀態(tài)向量拼在一起,得到向量序列 Mq;另外一種方式是把每個方向 RNN 的最后一個向量拿出來拼在一起,得到向量 q,用來整體表示問題句子。
知識編碼:使用了記憶網(wǎng)絡(Memory Network),對知識檢索階段得到的知識三元組分別進行編碼。針對一個三元組,用三個向量分別表示各部分,再將它們拼接在一起,變成一個向量 fi 來表示這個三元組,用 Mkb 表示所有三元組向量。
3. 解碼(Decoder):接下來根據(jù)答案和知識的編碼向量來生成自然答案。自然答案雖然是詞序列,但是不同的詞可能需要通過不同途徑獲得。例如:對于上述問題的答案“李連杰出生在北京,它現(xiàn)在是一個新加坡公民?!保~語“李連杰”需要從源問句中拷貝得到,實體詞“北京”,“新加坡”需要從知識庫中檢索得到,而其他詞如“出生”、“在”,“現(xiàn)在”等需要通過模型預測得到。因此,這里在標準的序列到序列(Sequence-to-Sequence)模型基礎上,融合了三種詞語獲得模式(包括拷貝、檢索和預測),用統(tǒng)一的模型對其建模,讓各種模式之間相互競爭相互影響,最終對復雜問題生成一個最好的自然答案。
為了檢驗模型的效果,論文分別在模擬數(shù)據(jù)集(由 108 個問答模板規(guī)則構造的問答數(shù)據(jù))和真實數(shù)據(jù)集(從百度知道獲取的 239,934 個社區(qū)問答數(shù)據(jù))上進行了實驗,在自動評估和人工評估上均取得了不錯的結(jié)果。
談到以后的工作,何世柱博士表示:“ COREQA 模型目前還是過于依賴學習數(shù)據(jù)。從實驗結(jié)果可以看出,在模擬的人工數(shù)據(jù)上幾乎可以有完美的表現(xiàn),但是在真實的數(shù)據(jù)上還是差強人意。究其原因還是該模型本質(zhì)是對原始數(shù)據(jù)的擬合,學習一個輸入問題(詞序列)到輸出答案(詞序列)的映射函數(shù),特別是非實體詞(即,不是拷貝和檢索得到的詞)常常預測得不準確。這是該模型最大的問題,我們計劃加入一些外部的人工知識對模型進行調(diào)整,對現(xiàn)有模型進行改進。另一個不足是目前只能利用三元組形式表示的知識庫,并假設答案實體就是三元組的 object 部分,其實該假設對很多問題并不成立,另一個可能的改進方向就是利用不同表示方式的知識庫。另外,該模型也可以應用于機器翻譯等任務,可以讓語言生成模型能外部知識資源進行交互?!?
而對于問答系統(tǒng)未來的發(fā)展,何世柱博士也有一些自己的的看法:“據(jù)我了解,真實的工程實踐上,問答系統(tǒng)還是使用模板和規(guī)則,很少或者根本不會用到統(tǒng)計模型,更別說深度學習的模型了。而目前在研究界,問答系統(tǒng)幾乎全部采用深度學習模型,甚至是完全端到端的方法。究其原因,我個人認為問答系統(tǒng)是一個系統(tǒng)工程,而不是一個純粹的研究任務,目前研究界對問答系統(tǒng)還沒有一個統(tǒng)一的范式(不像信息檢索、機器翻譯、信息抽取等任務),因此,未來問答系統(tǒng)可能需要總結(jié)出一個或幾個通用范式和流程,可以分解為若干子任務,這樣會更易于推動問答的研究發(fā)展。另外,問答系統(tǒng)效果無法達到實用,其問題還沒有分析清楚,是知識資源不完備,還是知識表示的異構性,或者是理解自然語言問題的挑戰(zhàn)?最后,我認為,問答系統(tǒng)這類需要大量知識的任務,在數(shù)據(jù)規(guī)模難以大規(guī)模擴展的情況下,融合統(tǒng)計模型和先驗知識(萃取的知識庫、語言知識、常識等)是可行的發(fā)展方向?!?/div>
那么具體是怎么做的呢? 這里以“你知道李連杰來自哪里嗎?” 這個問題為例來說明:
1. 知識檢索:首先要先識別問題中的包含的實體詞。這里我們識別出的實體詞是:李連杰。然后根據(jù)實體詞從知識庫(Knowledge Base,KB)中檢索出相關的三元組(主題,屬性,對象)。針對李連杰這個實體,我們可以檢索出(李連杰,性別,男),(李連杰,出生地,北京),(李連杰,國籍,新加坡)等三元組。
2. 編碼(Encoder):為了生成答案,我們需要將問題和檢索到的知識編碼成向量,以便后續(xù)深度生成模型利用。
問題編碼:使用了雙向 RNN(Bi-RNN),用兩種方式來表示問題:一種是將兩種方向 RNN 狀態(tài)向量拼在一起,得到向量序列 Mq;另外一種方式是把每個方向 RNN 的最后一個向量拿出來拼在一起,得到向量 q,用來整體表示問題句子。
知識編碼:使用了記憶網(wǎng)絡(Memory Network),對知識檢索階段得到的知識三元組分別進行編碼。針對一個三元組,用三個向量分別表示各部分,再將它們拼接在一起,變成一個向量 fi 來表示這個三元組,用 Mkb 表示所有三元組向量。
3. 解碼(Decoder):接下來根據(jù)答案和知識的編碼向量來生成自然答案。自然答案雖然是詞序列,但是不同的詞可能需要通過不同途徑獲得。例如:對于上述問題的答案“李連杰出生在北京,它現(xiàn)在是一個新加坡公民?!保~語“李連杰”需要從源問句中拷貝得到,實體詞“北京”,“新加坡”需要從知識庫中檢索得到,而其他詞如“出生”、“在”,“現(xiàn)在”等需要通過模型預測得到。因此,這里在標準的序列到序列(Sequence-to-Sequence)模型基礎上,融合了三種詞語獲得模式(包括拷貝、檢索和預測),用統(tǒng)一的模型對其建模,讓各種模式之間相互競爭相互影響,最終對復雜問題生成一個最好的自然答案。
為了檢驗模型的效果,論文分別在模擬數(shù)據(jù)集(由 108 個問答模板規(guī)則構造的問答數(shù)據(jù))和真實數(shù)據(jù)集(從百度知道獲取的 239,934 個社區(qū)問答數(shù)據(jù))上進行了實驗,在自動評估和人工評估上均取得了不錯的結(jié)果。
談到以后的工作,何世柱博士表示:“ COREQA 模型目前還是過于依賴學習數(shù)據(jù)。從實驗結(jié)果可以看出,在模擬的人工數(shù)據(jù)上幾乎可以有完美的表現(xiàn),但是在真實的數(shù)據(jù)上還是差強人意。究其原因還是該模型本質(zhì)是對原始數(shù)據(jù)的擬合,學習一個輸入問題(詞序列)到輸出答案(詞序列)的映射函數(shù),特別是非實體詞(即,不是拷貝和檢索得到的詞)常常預測得不準確。這是該模型最大的問題,我們計劃加入一些外部的人工知識對模型進行調(diào)整,對現(xiàn)有模型進行改進。另一個不足是目前只能利用三元組形式表示的知識庫,并假設答案實體就是三元組的 object 部分,其實該假設對很多問題并不成立,另一個可能的改進方向就是利用不同表示方式的知識庫。另外,該模型也可以應用于機器翻譯等任務,可以讓語言生成模型能外部知識資源進行交互?!?
而對于問答系統(tǒng)未來的發(fā)展,何世柱博士也有一些自己的的看法:“據(jù)我了解,真實的工程實踐上,問答系統(tǒng)還是使用模板和規(guī)則,很少或者根本不會用到統(tǒng)計模型,更別說深度學習的模型了。而目前在研究界,問答系統(tǒng)幾乎全部采用深度學習模型,甚至是完全端到端的方法。究其原因,我個人認為問答系統(tǒng)是一個系統(tǒng)工程,而不是一個純粹的研究任務,目前研究界對問答系統(tǒng)還沒有一個統(tǒng)一的范式(不像信息檢索、機器翻譯、信息抽取等任務),因此,未來問答系統(tǒng)可能需要總結(jié)出一個或幾個通用范式和流程,可以分解為若干子任務,這樣會更易于推動問答的研究發(fā)展。另外,問答系統(tǒng)效果無法達到實用,其問題還沒有分析清楚,是知識資源不完備,還是知識表示的異構性,或者是理解自然語言問題的挑戰(zhàn)?最后,我認為,問答系統(tǒng)這類需要大量知識的任務,在數(shù)據(jù)規(guī)模難以大規(guī)模擴展的情況下,融合統(tǒng)計模型和先驗知識(萃取的知識庫、語言知識、常識等)是可行的發(fā)展方向?!?/div>





